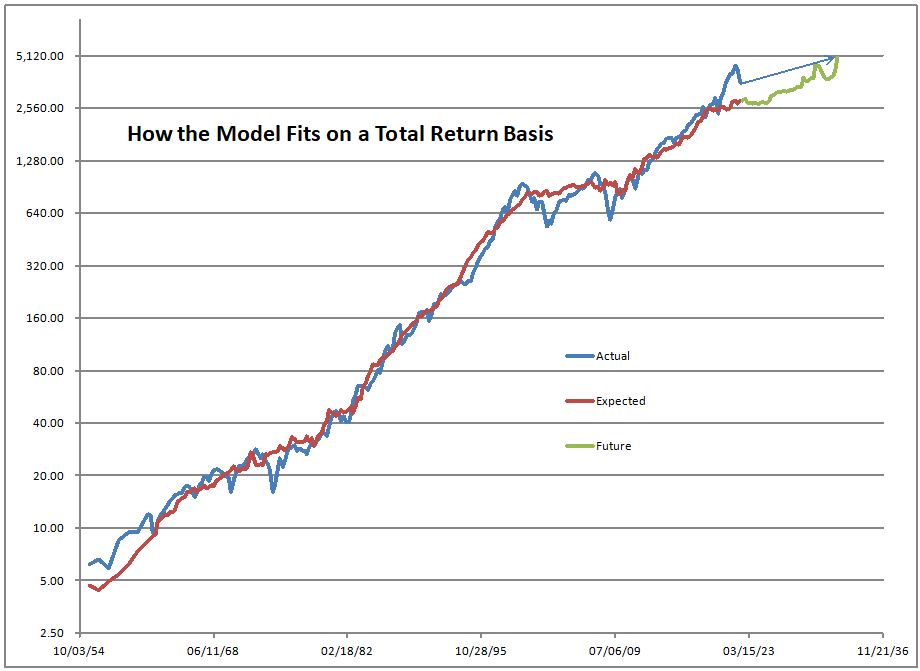
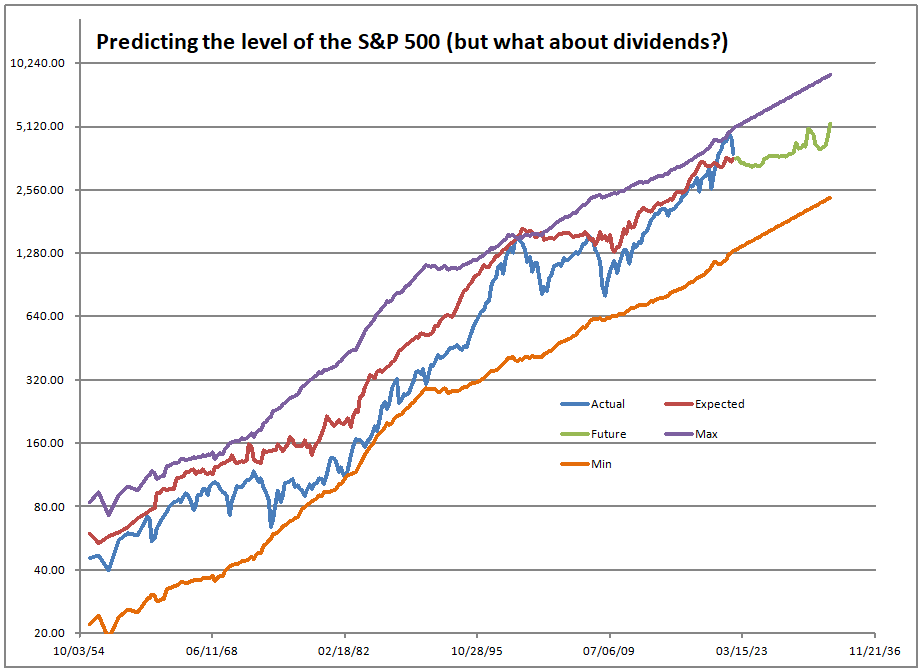
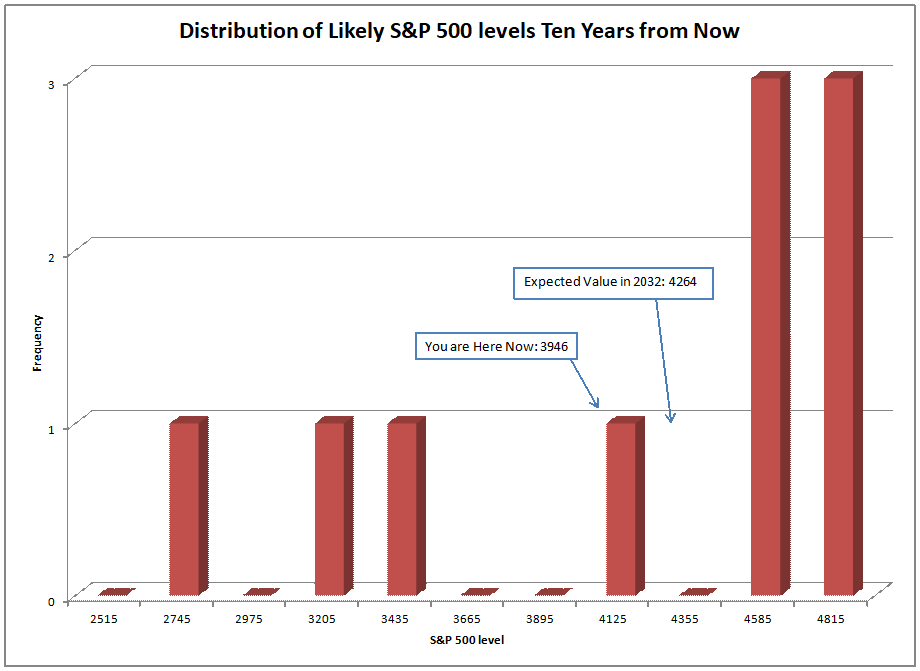
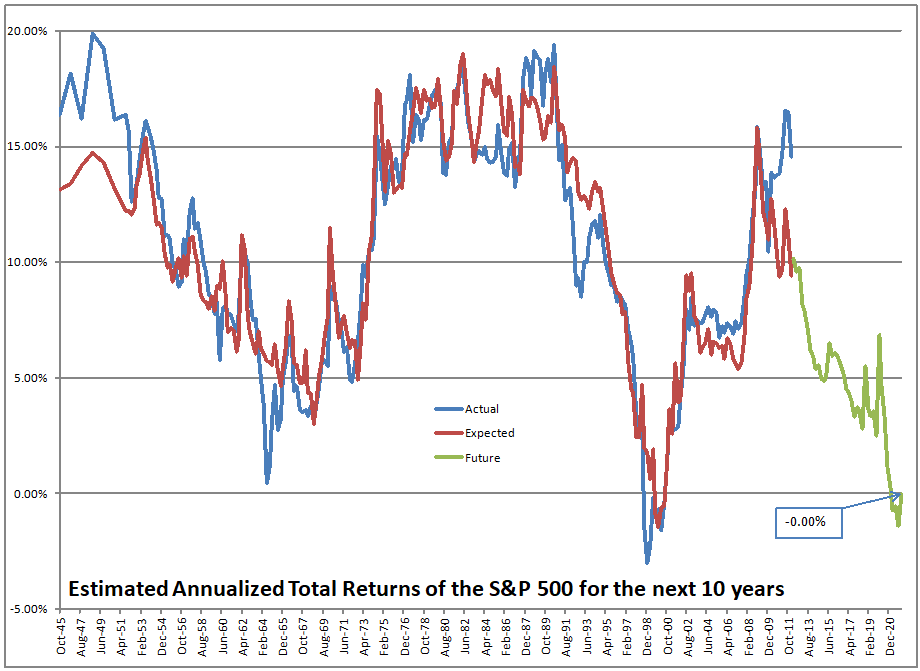
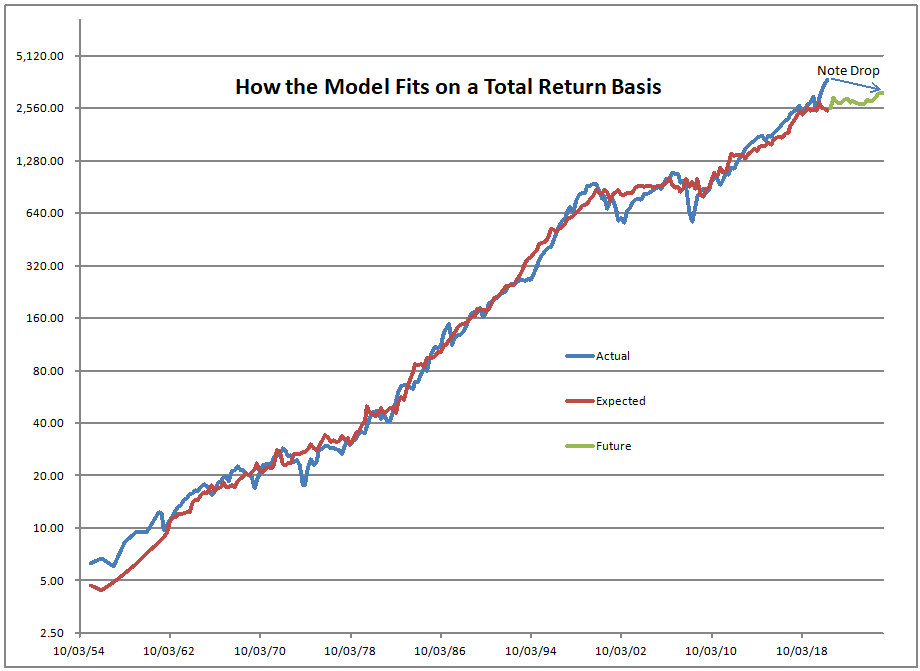
Image Credit: Aleph Blog || The model fits the data well
I don’t plan on doing this often, but I got a number of good responses on the last article, and I want to answer them in a more complete way, rather than doing it in the comments, where they for practical purposes never get read.
Thanks for sharing your estimates and work on the average investor equity allocation. I recently wrote an email to you asking if you have done similar studies for other countries. I read that while the US has 45% the UK is at 10% average equity allocation. Have you seen if the average equity allocation can be applicable model for other countries or you reckon everything moves together with the S&P? The Hang Seng for example gained after the dot com bubble and was not flat to down in 10 years. Peak was 7 years later� this could be an opportunity to outperform if you are selective because while you are saying avoid large cap growth names it is worth noting that the US has outperformed the world last 10 years since Osama died and the USD has been the strongest currency. It may be the case of avoid US stocks here and be aggressive in Australia which has value oriented index and has been flat since GFC.
https://alephblog.com/2021/06/18/estimating-future-stock-returns-march-2021-update/#comment-39991
I haven’t run into any other nation where there is sufficient data to do what I am doing here. Remember, the data from the Fed’s Z.1 report include estimates of the value of private assets. I can’t believe the 10% number for the UK. That has to be wrong… it is probably not counting private assets, and may only be counting direct holdings by individuals and not those of institutions.
Is this CAPE forward returns, or the money-flow based model?
Also, how do you think about the fact that CAPE Excess spread is still positive?
Thanks.
https://alephblog.com/2021/06/18/estimating-future-stock-returns-march-2021-update/#comment-39992
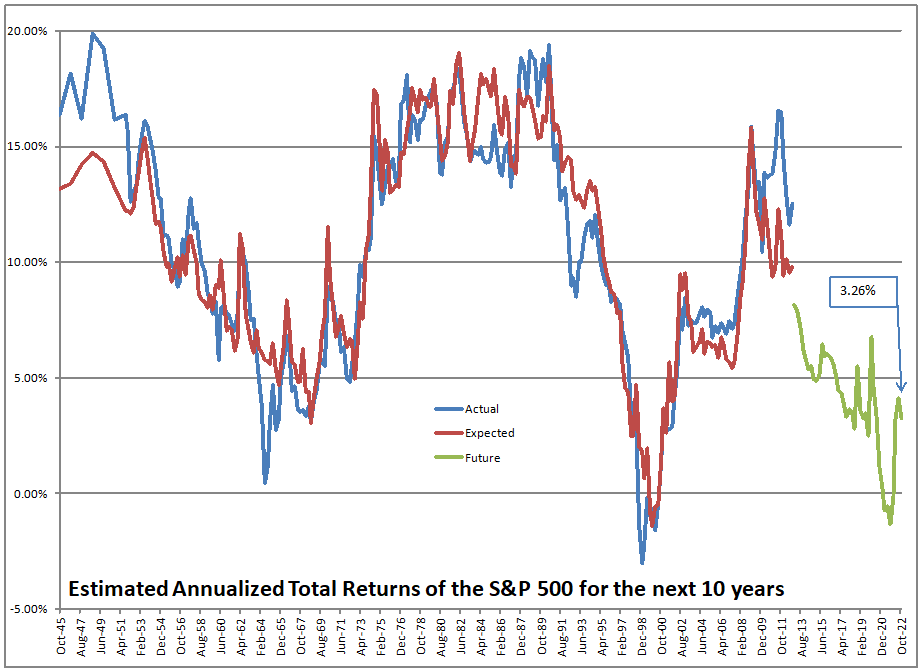
Neither. This is the asset share model, not the CAPE, which less accurate than this model. I have no idea regarding the CAPE Excess spread. I don’t pay attention to that.
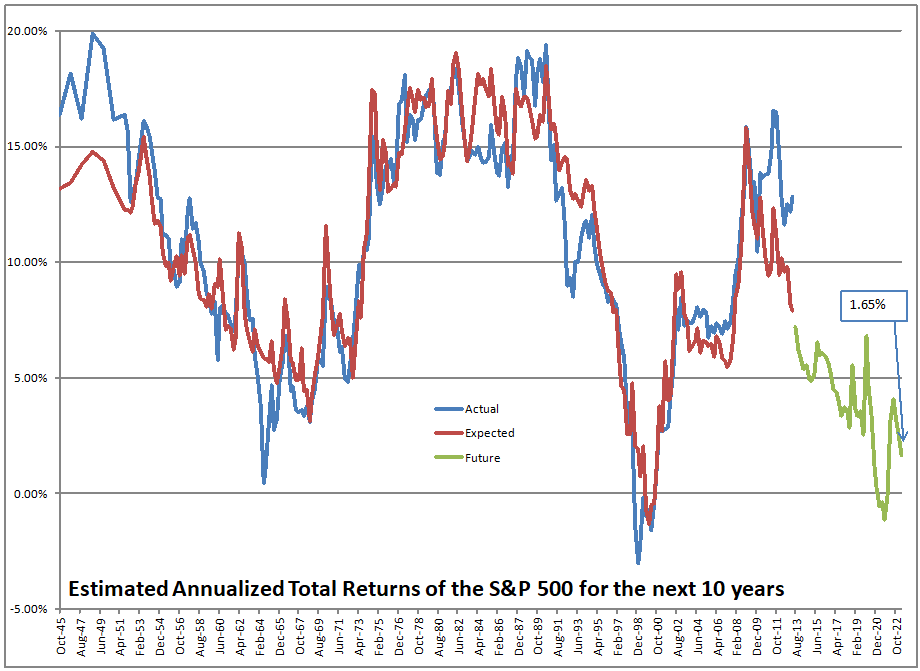
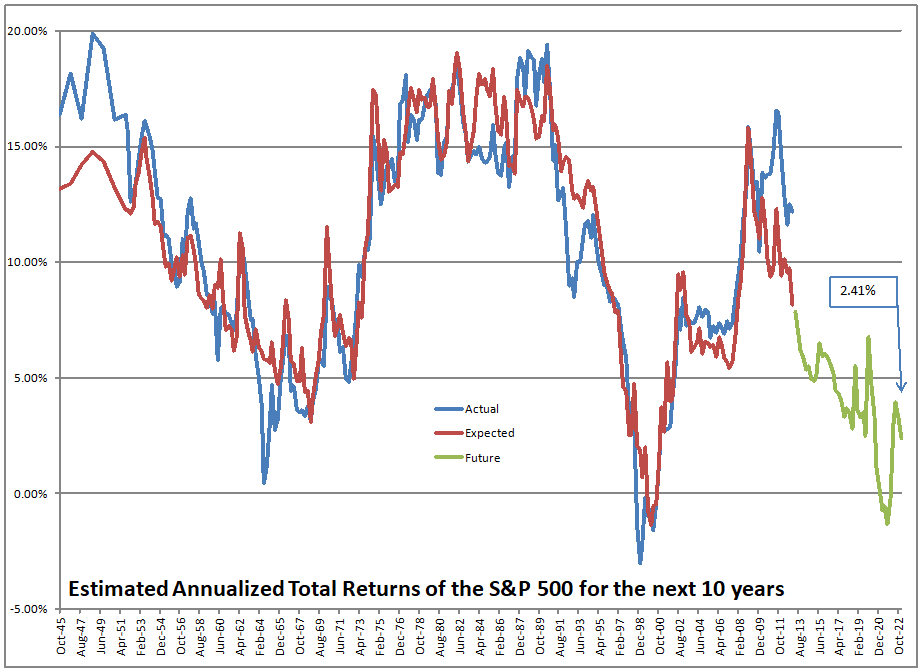
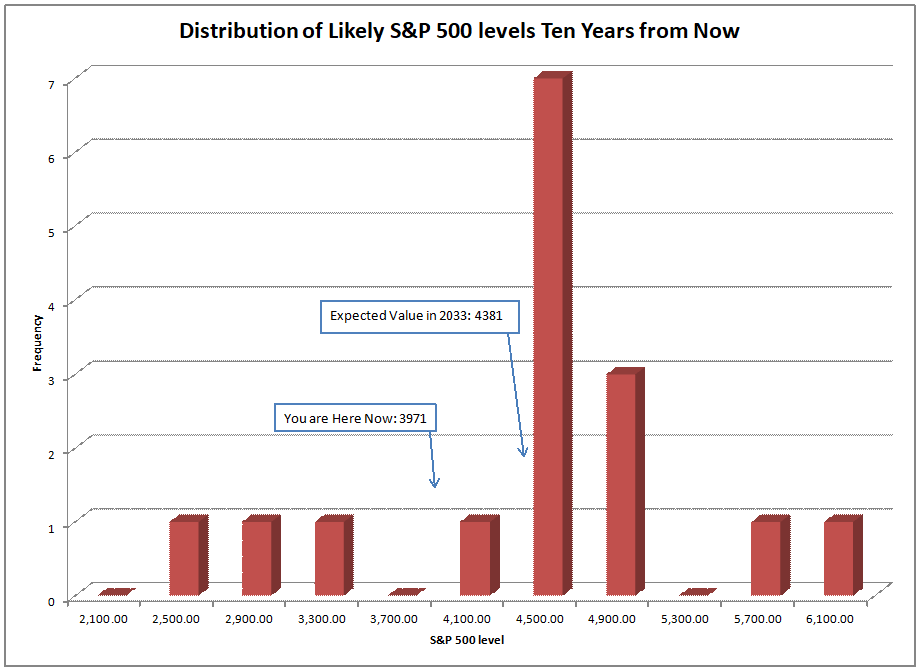
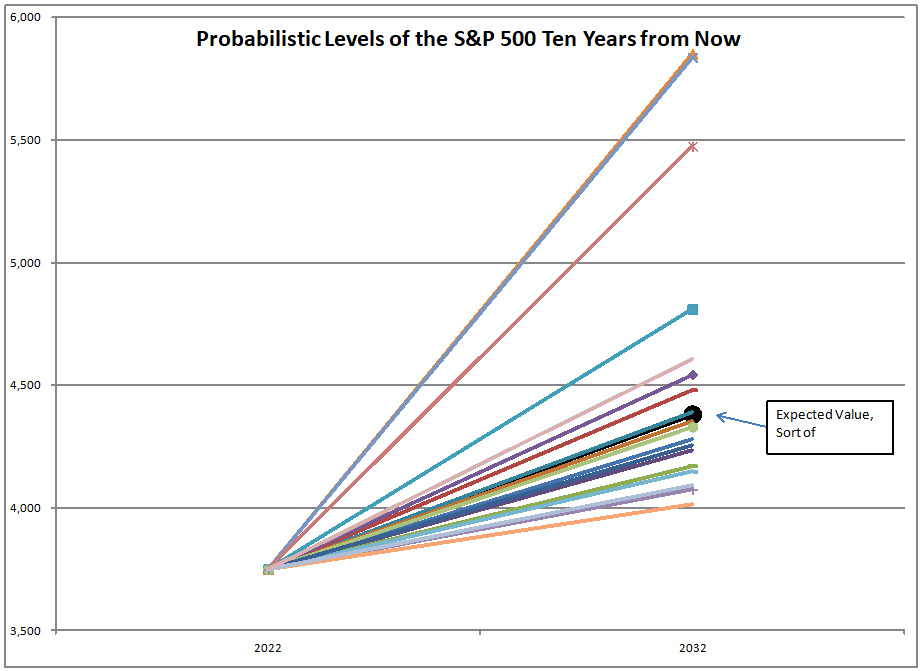
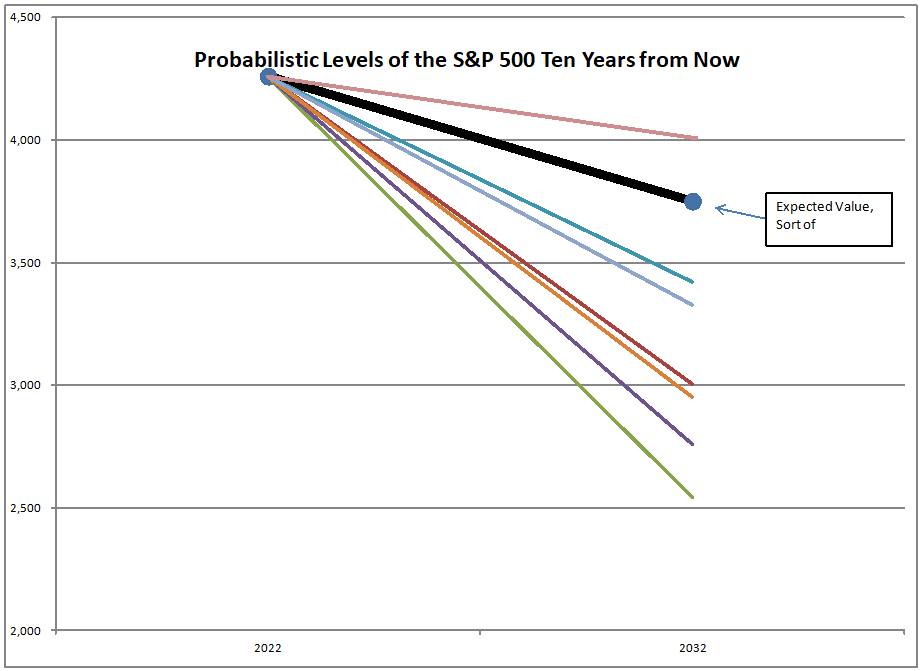
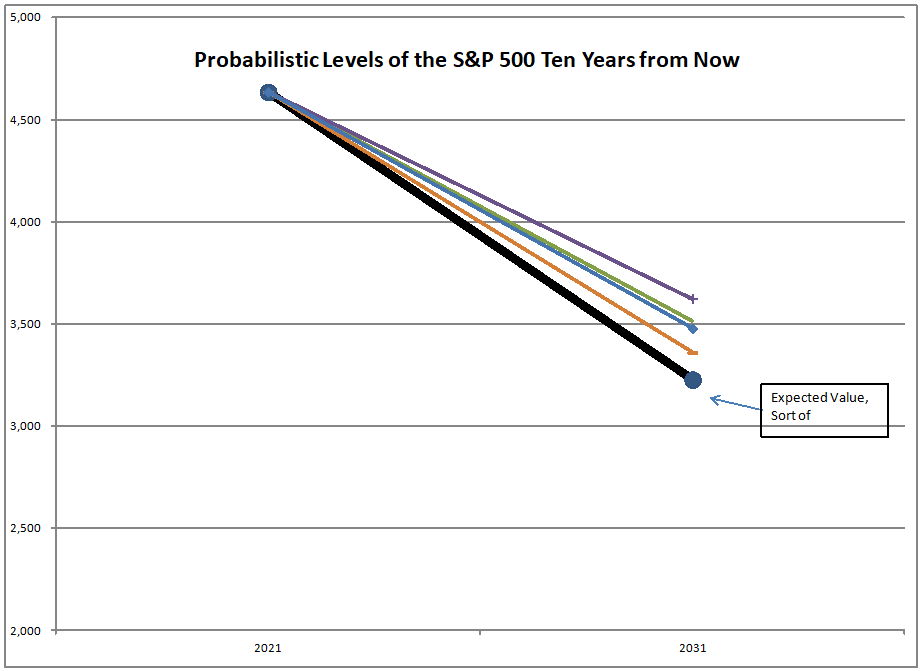
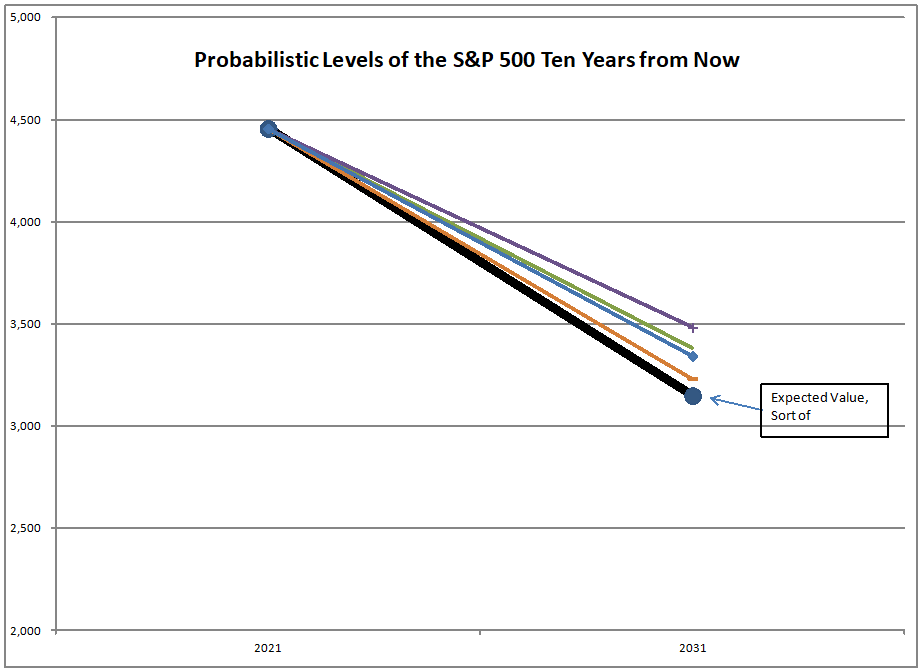
The asset share model measures the percentage of assets held by Americans in stocks. The highest figure ever is 52.3%, the lowest is 21.8%. When the value is high, future returns are low, and vice-versa. We are over 51% at present.
The bailouts always favor the rich. As I am sure you know, people like Charlie Munger have basically said that the peasants should shut up and be grateful because if the rich hadn�t been bailed out (bailouts are ongoing), the peasants would have had an even worse outcome.
Sheila Bair had a plan to go into these financial firms and do a few things: 1. protect depositors 2. fire management 3. re-open by selling to a healthy firm. She was laughed out of the room, and resigned (around 2008).
Never forget that all the rich folks you see on CNBC, even Warren Buffet, were bailed out. I wasn�t. Luckily I had taken action to retain most of my gains, so I did pretty well. These people that are supposed to be so much smarter than the rest of us? Probably not so much. They are just in the right club.
https://alephblog.com/2021/06/18/estimating-future-stock-returns-march-2021-update/#comment-39993
Charlie Munger is a bright guy, but he’s wrong here. Anyone reading Aleph Blog during the Financial Crisis knows that I did not favor the bailouts, and that I would not have minded another depression. That’s an unpopular view, but it would have punished the rich for borrowing too much. It would have leveled the playing field, and things would have normalized within ten years.
People forget the the promiscuous monetary policy of the Fed set us up for both crises 1929 and 2008. It’s setting us up for another one now. BTW, Buffett did not get bailed out. He didn’t need it with his fortress balance sheet.
You�ve persuaded me. How do I persuade my young?
https://alephblog.com/2021/06/18/estimating-future-stock-returns-march-2021-update/#comment-39994
That’s a tough question. I raised eight children, who all got to listen to me for a long time. Only three out of eight ended up doing well in their finances. (Two are stay-at-home moms who married the right guys. Note: the good ones marry early. Those who purposely delay marriage typically have troubles.) Four are marginal, and one is a total failure. Did I expect better? Yes. but once the arrow leaves the string, you can’t influence it any more.
One of the smartest guys I know said to me, “Once they become adults, don’t say anything, but pray for them a lot.” I think he is correct, though if a teachable moment comes, seize it.
I think most people have to pay “market tuition.” Losses teach investors a lot, and do much good, so long as the investor does not give up. Those that give up will likely never learn.
The children of mine that are succeeding ask my advice. Now, you could tell your kids about Aleph Blog, but they might find me boring.
Given the extreme valuations of the market and exuberant behavior by average investors, I wonder if even deep value stocks and funds will provide a reasonable return going forward. What worked back in 2000 � 2010 may not work this time around. I currently like Aegis Value (AVALX) which is heavily invested in resource stocks including precious metal miners. Manager is a deep value investor with portfolio currently having a P/B of 0.8 and average stock market cap < $800M. This fund outperformed during the 2000 to 2010 bear market but does lag during times when growth stocks are in vogue. Currently looking for other deep value funds to protect capital over the next 10 years. Just wish T. Rowe Price Capital Appreciation was still open. I�m thinking maybe a good balanced fund from Dodge & Cox or Oakmark might be a worthy holding at this point.
https://alephblog.com/2021/06/18/estimating-future-stock-returns-march-2021-update/#comment-39995
Those are credible investments, and seem reasonable to me. There is still a huge valuation gap between growth and value stocks. I am not worried about value here.
There are ways to get shares of funds that are closed, but you might have to pay a premium to get them.
Any thoughts about the attractiveness of local-currency (or hard) emerging sovereign bonds at this point in time?
https://alephblog.com/2021/06/18/estimating-future-stock-returns-march-2021-update/#comment-39996
If the Fed is moving to tighten, or even taper, these are not good ideas. I lost money in those asset classes after Bernanke uttered “taper.” Emerging market debt typically does not do well when the Fed is tightening policy.
IMO valuations will go higher than the last tech bubble. Trend over time has been bubbles getting bigger and valuations getting higher. Accommodative FED, low interest rates will support the market and technology which is truly changing the world will cause euphoria in investors and the market. We have a ways to go before the top is in, IMO.
I work in the tech industry (software for years, now in IT), and I see the world moving to the cloud in droves. I see the SAAS companies growing 30-100%+ per year in revenue. Yes they are 20-50x sales valuations, but when you are growing that fast and your growth is accelerating every quarter, and it�s obvious the entire world is going to be using your product in the near future, what is the proper value? All I can do is buy on pullbacks, and wait for euphoria signals like the 90s (CNBC on the tv at the country club instead of ESPN, stuff like that). When I start seeing that stuff, I�ll sell some on pops, and then trail the rest with a moving average to get me out after the bubble pops.
David I believe you are a very smart guy, and a very good investor. As with most good value investors, they are early. Just my opinion.
https://alephblog.com/2021/06/18/estimating-future-stock-returns-march-2021-update/#comment-39997
I think you are a good investor as well, but you fish in a different pool than I do. Yes, I know value investors are early. When I worked for a value-oriented hedge fund, I was the the “black sheep” that looked at momentum and tried to coax my associates out of short positions that looked doomed.
I am not as sanguine as you, but you know that. The model that I use implies that there are limits to how high or low equity valuations can get. We are near that top now. The dot-com bubble was worse then the bubble before the financial crisis as far as the equity markets go, though the financial crisis was more severe for the economy as a whole, as it affected the banks.
On a macroeconomic basis, my concern is that the Fed will run into a zugzwang situation where they have to choose from two bad options. Personally, I think they will choose to deflate, but really, who knows? They tend to favor the unlevered rich, and not the working poor.
Dumb question but when you say the expected returns are under 1% are you simply just doing an inverse of the current S&P PE ratio, which is around 44?
https://alephblog.com/2021/06/18/estimating-future-stock-returns-march-2021-update/#comment-39998
That’s not a dumb question. No, that’s not what I am doing. I am using the asset share model. The asset share model measures the percentage of assets held by Americans in stocks. The highest figure ever is 52.3%, the lowest is 21.8%. When the value is high, future returns are low, and vice-versa. We are over 51% at present.
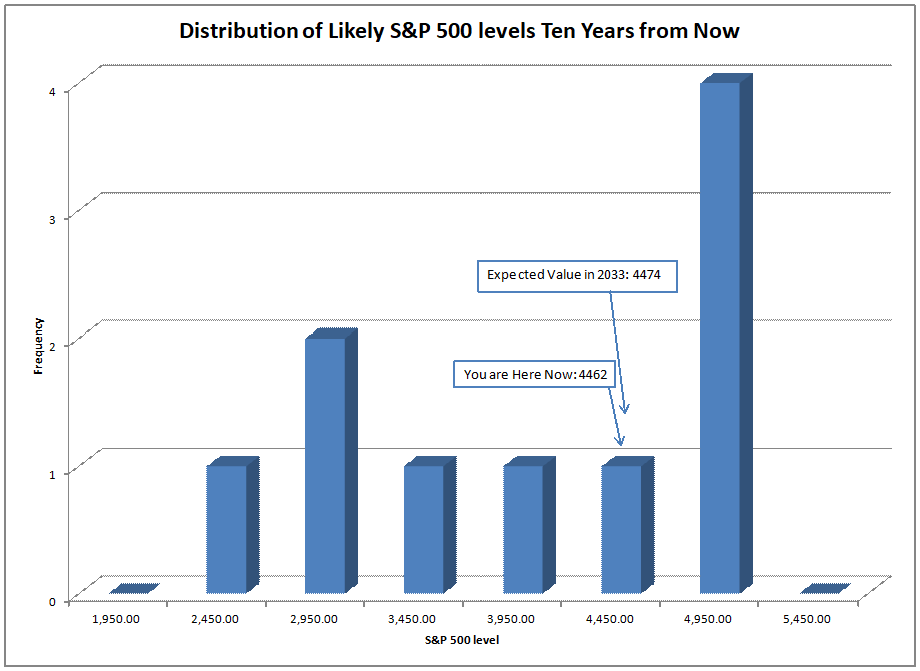
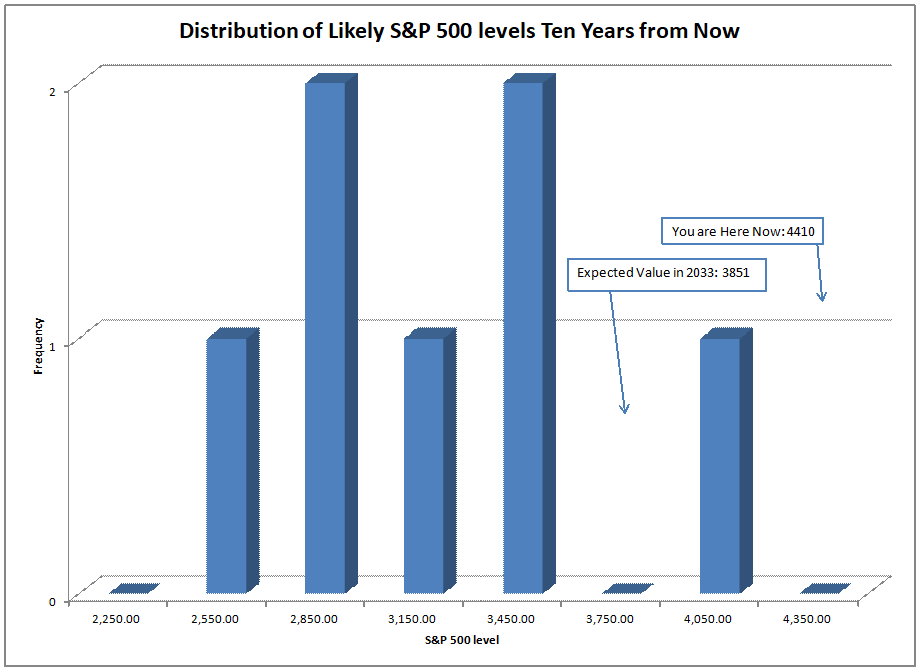
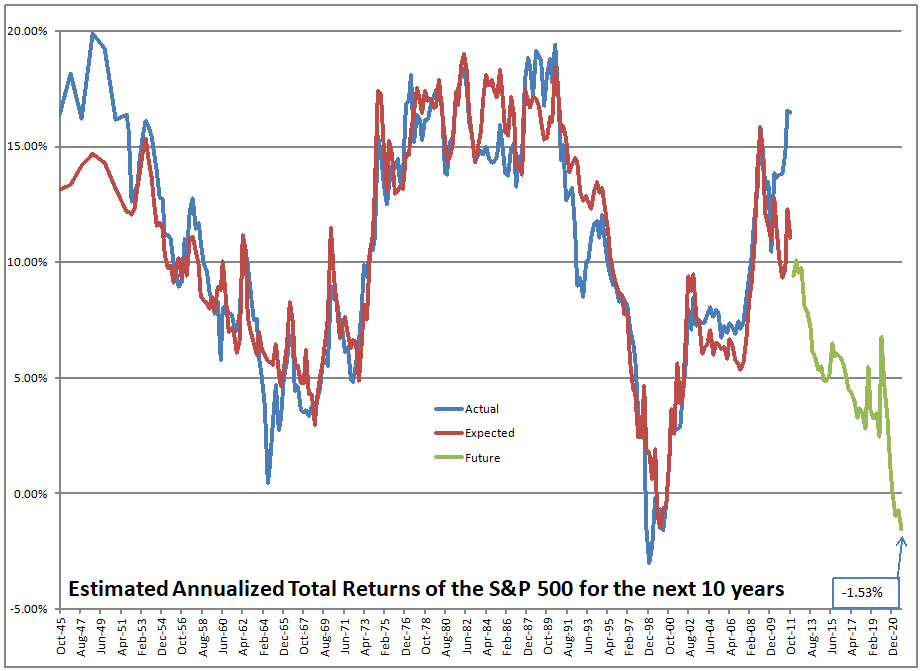
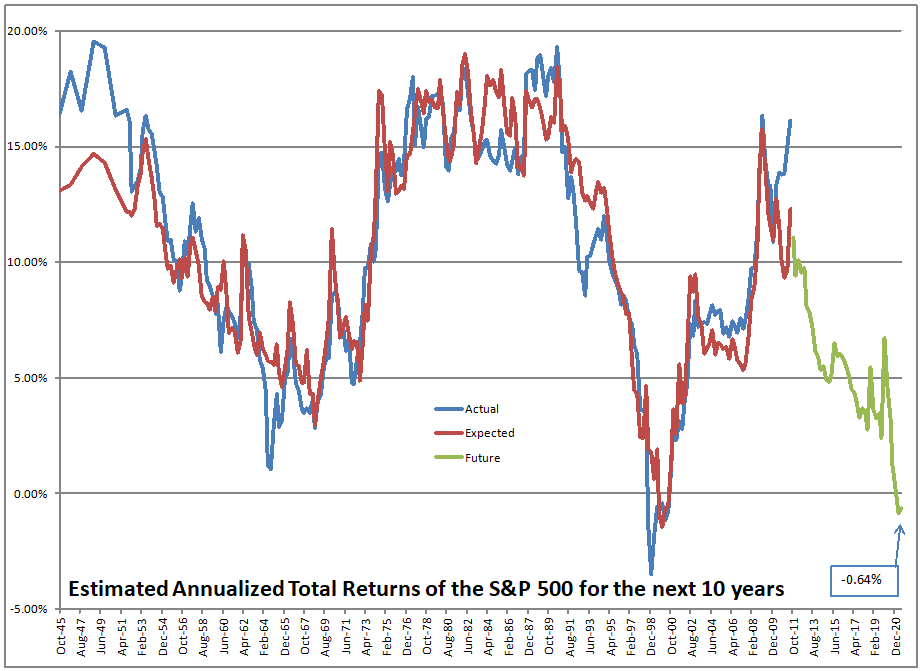
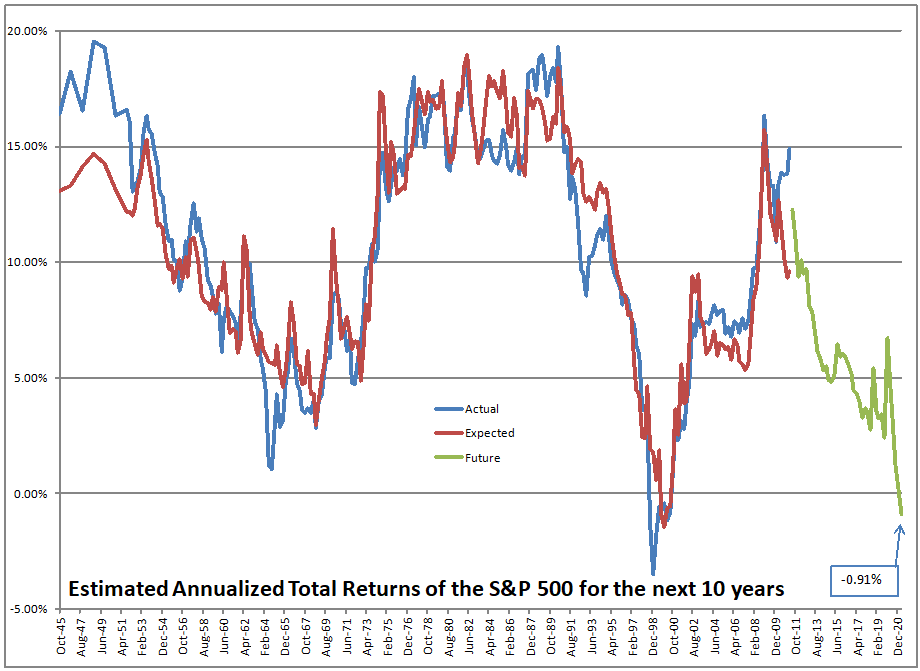
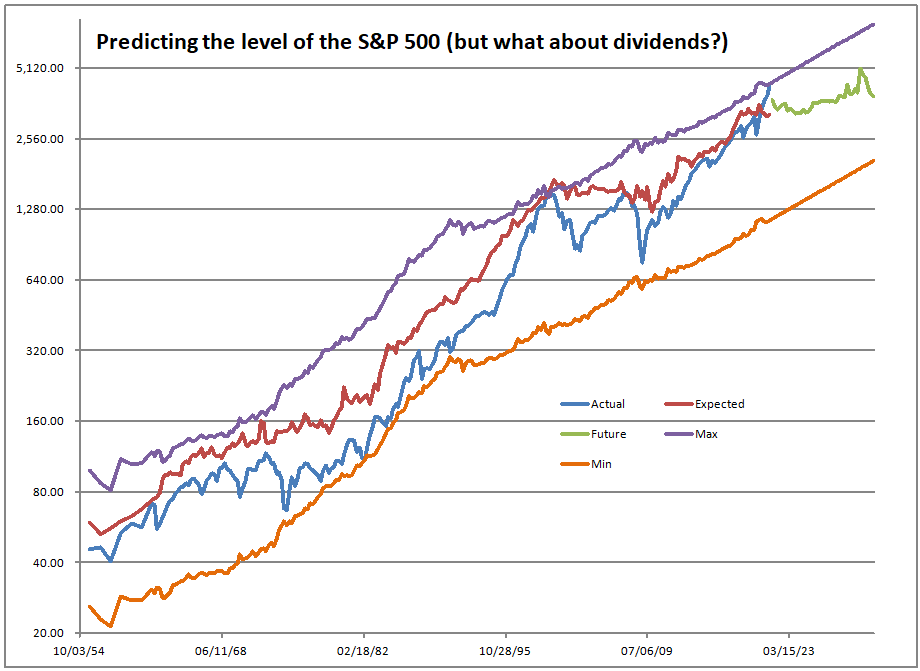
Using what the asset share for stocks was in the past, I run a regression to calculate how sensitive 10-year returns on the S&P 500 are to the asset share of stocks. Then I use that equation to forecast future performance. At present the model is forecasting returns of -0.91%/year over the next ten years, not adjusted for inflation.
To those asking how David calculates this, the model is here:
https://alephblog.com/2016/04/16/estimating-future-stock-returns-follow-up/
https://alephblog.com/2021/06/18/estimating-future-stock-returns-march-2021-update/#comment-40000
Thank you for saying that. And hey, you got comment 40,000. Well done.
Now that said, I should add one thing. Roughly one year ago, I figured out how to more accurately estimate the values between the quarterly data that the Fed puts out. I ran some regressions to estimate how much money goes into stocks and everything else, independent of returns on the asset classes. It has made the model work better over the last two years.
=========================
At Aleph Blog, I try to say what I think is true, whether it is popular or not. I think we are in a precarious place at present and am reducing risk. I don’t think there is much upside in this environment, aside from some safe and boring value stocks, and those only maybe — but that is where my money is, along with 30% in very short fixed income.