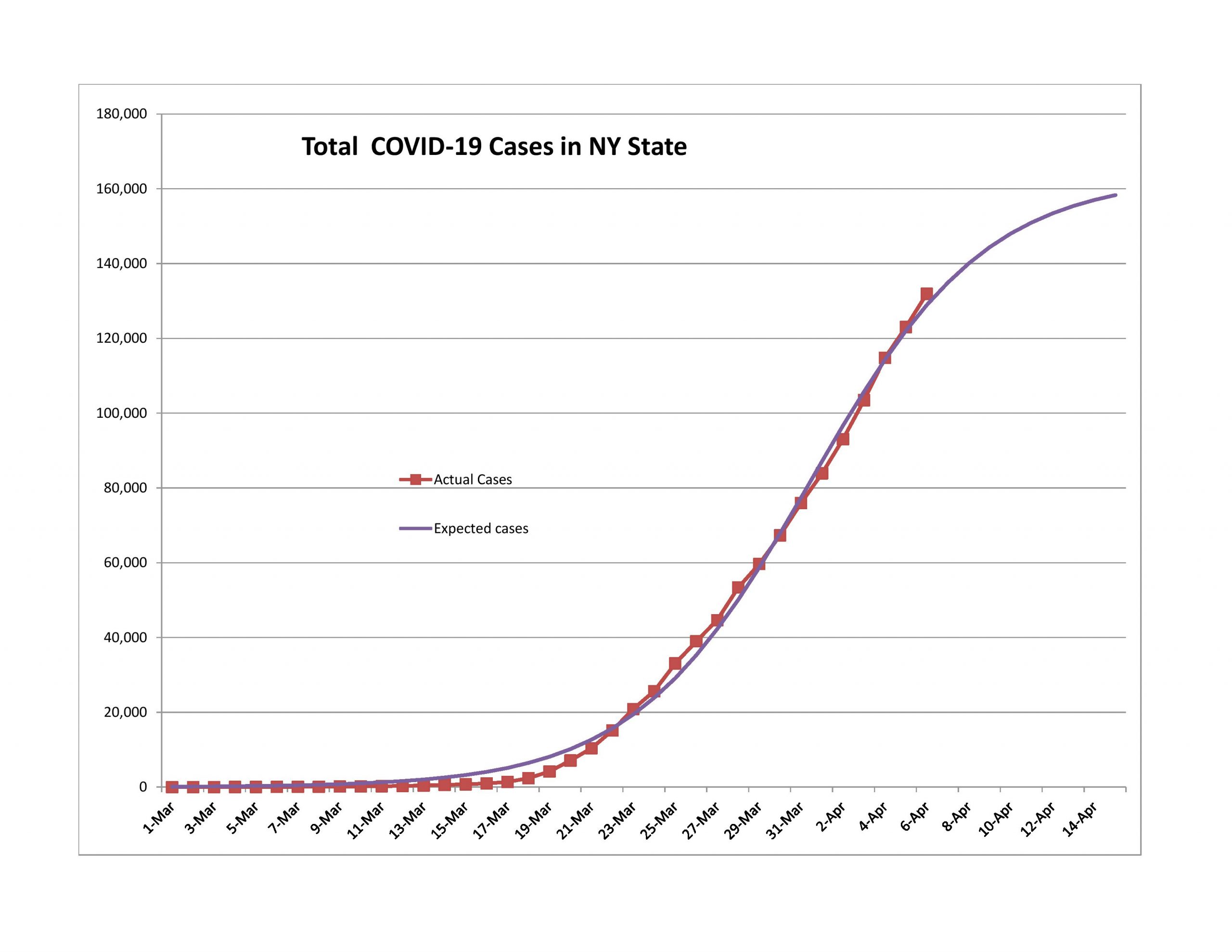
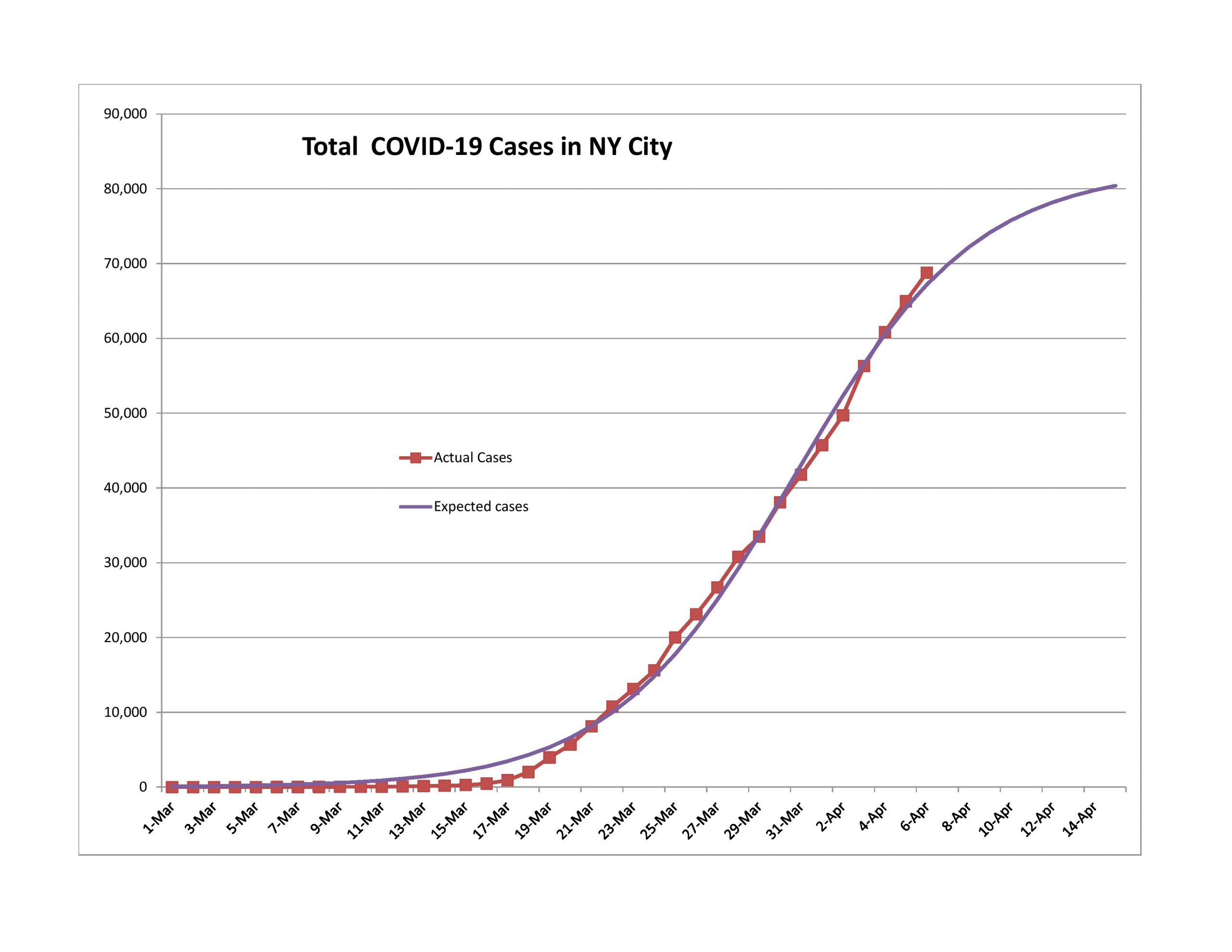
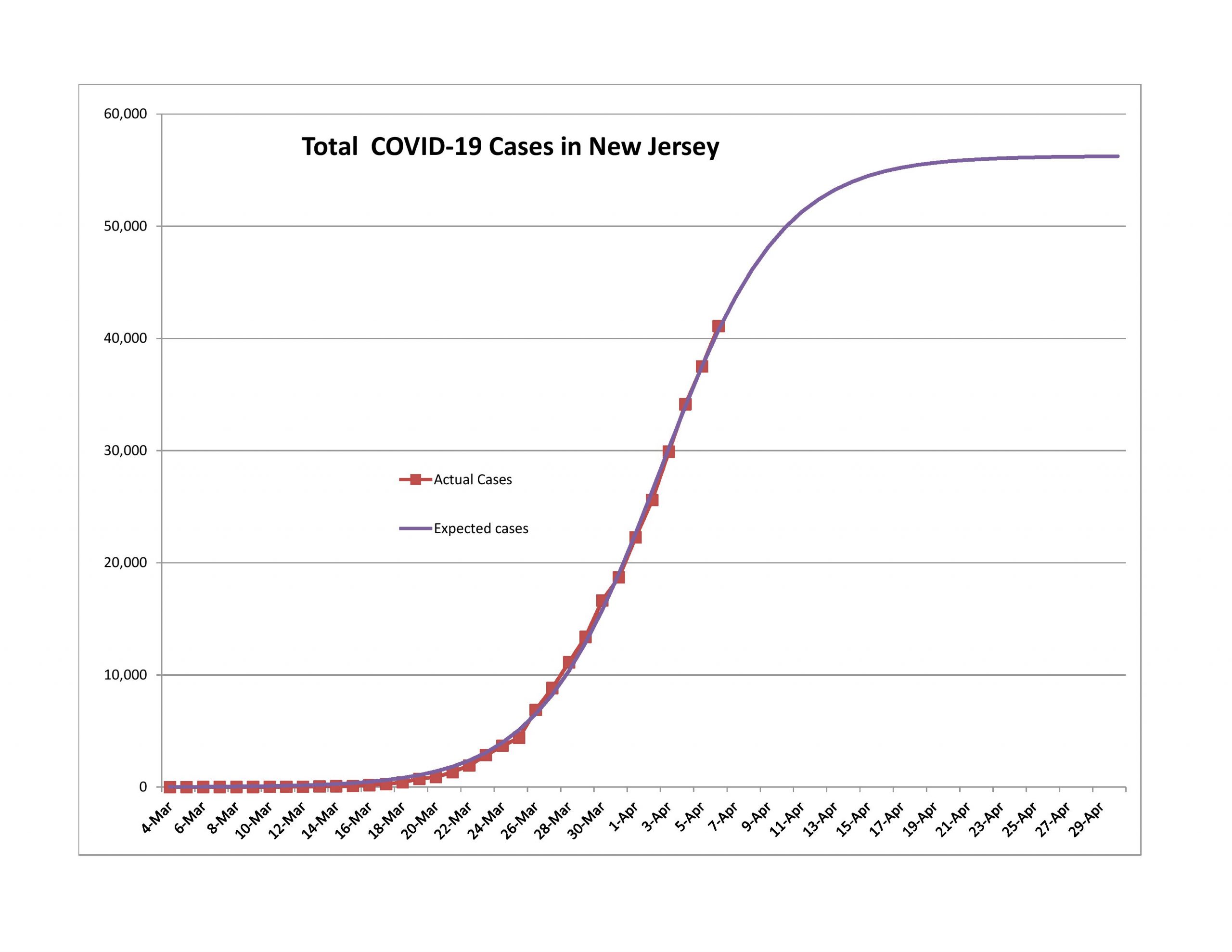
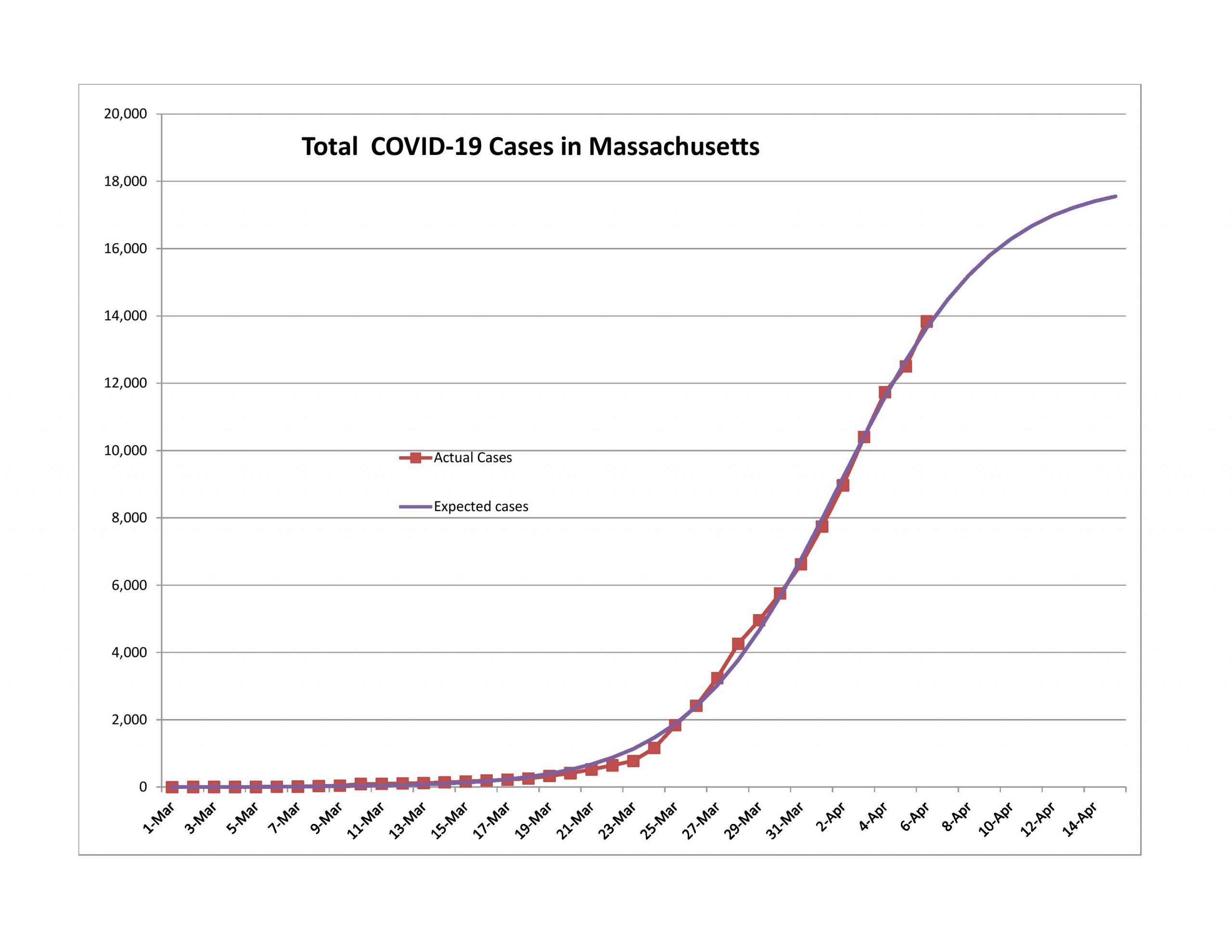
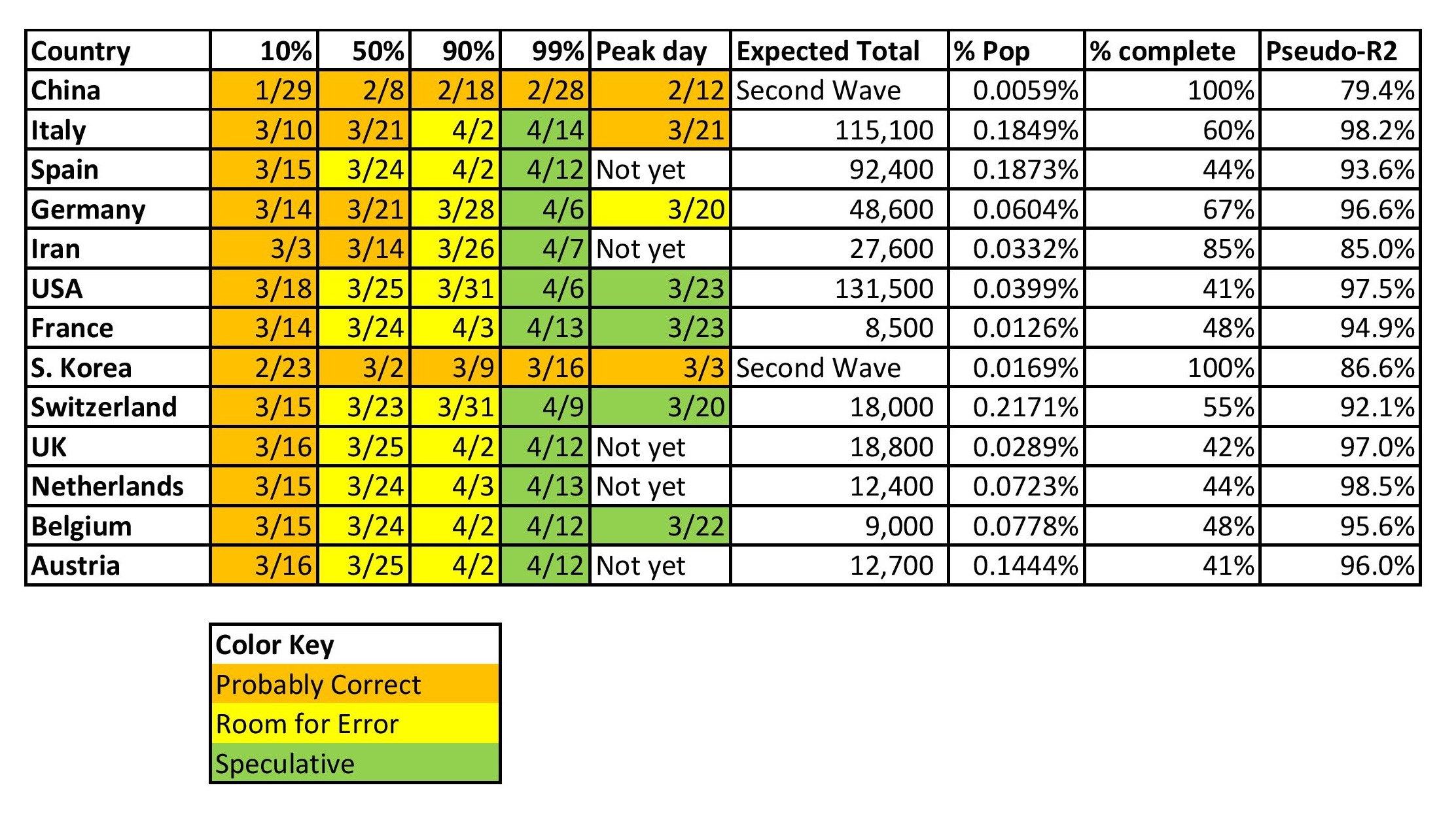
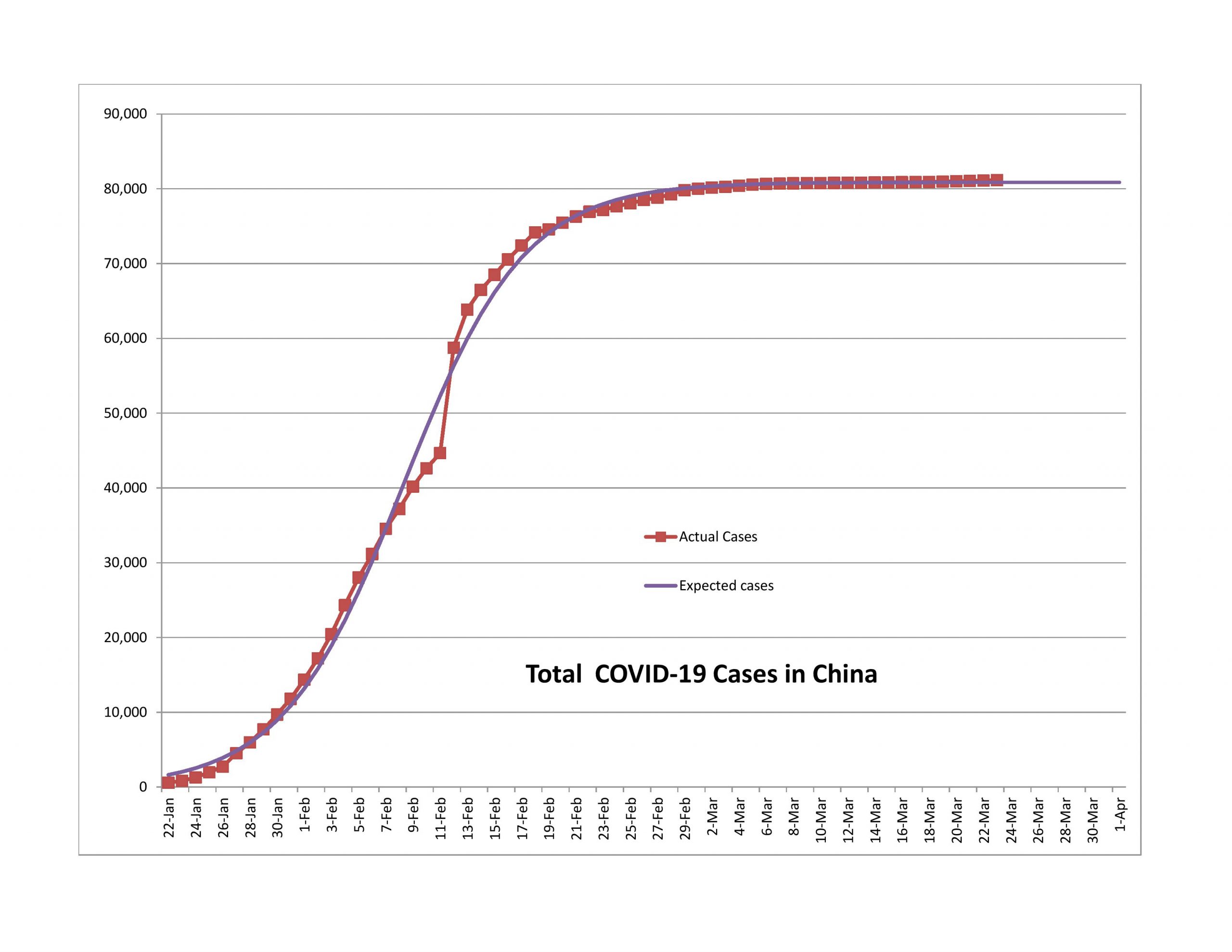
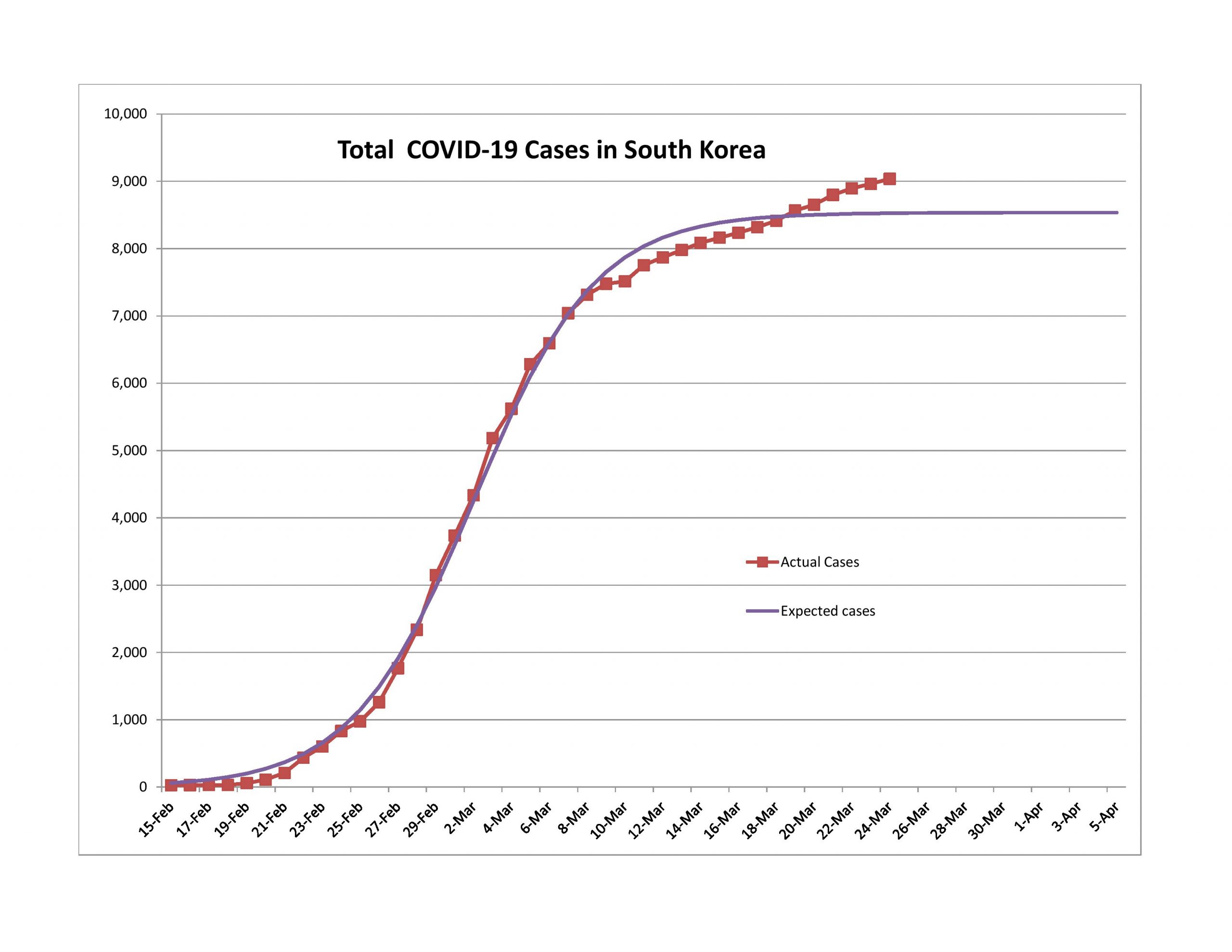
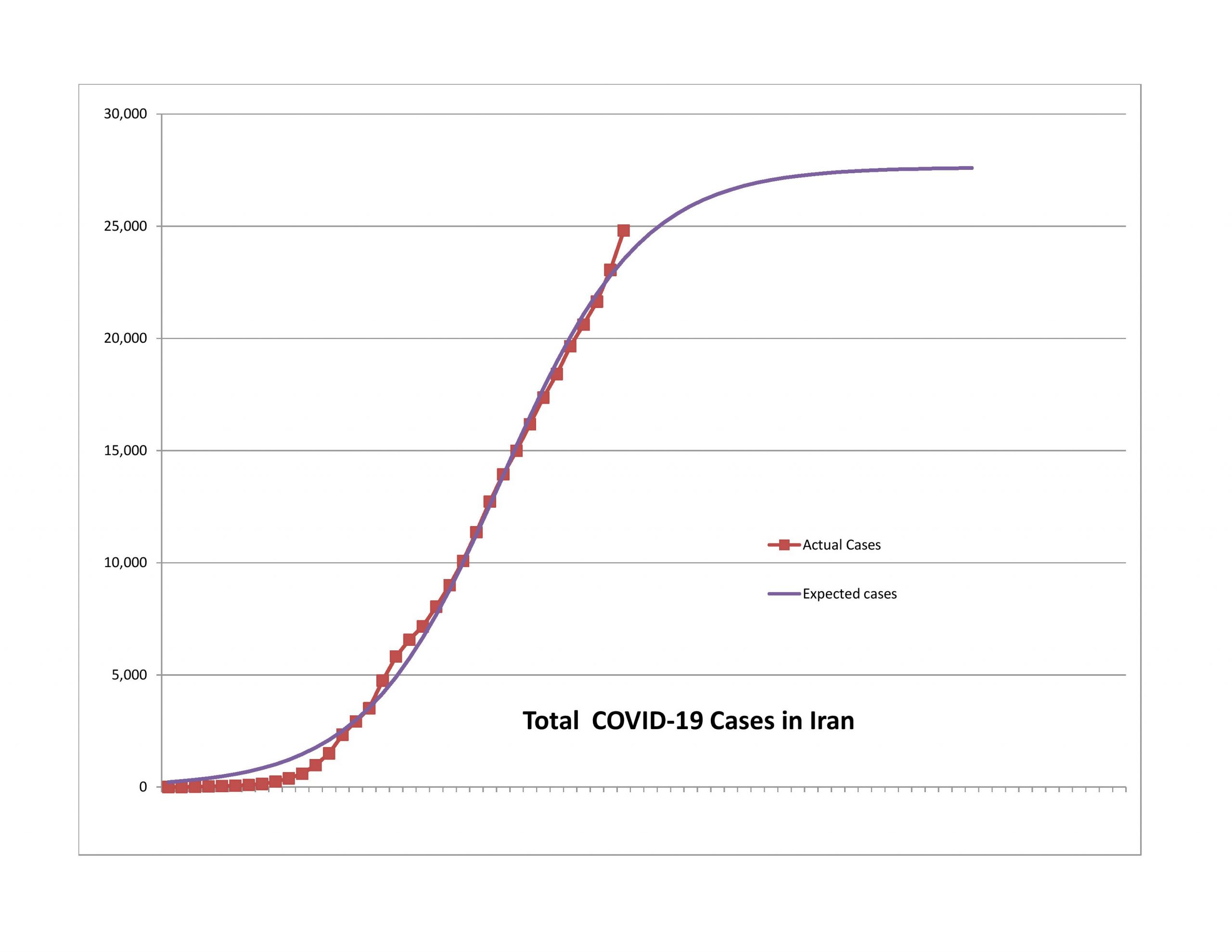
Should You Become an Actuary?
Image credit: Word Cloud by�Epic Top 10 || It is a great profession, but for most people, the exams are tough.
Note: at the end of this article, there is a note on GameStop.
Here’s a letter from a reader:
David,
I am a longtime reader of your blog, which I enjoy greatly. I will retire from the military in about three years and am considering becoming an actuary via self-study and taking the requisite exams. Given your experience in the field, I would like to ask you some questions:1.������ If I do this, will anyone hire me, or is this field one that strictly recruits new graduates from certain established schools?� My degrees are in Chemical and Aeronautical�Engineering (BS & MS respectively) if that matters.
2.������ �If this is a reasonable path to take, which organization�s certifications should I pursue (SoA or CAS)?
3.������ How do I go about applying for positions outside of a formal recruitment process (e.g. one established for recent graduates)?
Thank you for your time and attention.
Recent email
I haven’t gotten an email like that in a while. You can become an actuary if you are good at math, statistics, quantitative methods, and are reasonably good at taking exams. That can get you in the door, but oddly, there ‘s another set of skills that the best actuaries have. Let me phrase it in terms of questions:
- Do you like solving business problems?
- Can you write and speak well in the language of the company that you want to work for?
- Can you come up with creative solutions to problems?
- Do you like solving mysteries, without forgetting that time is limited?
- It is helpful to have a few ancillary skills like programming, knowledge of accounting, investing, business, economics, law, etc. You can pick up a lot on the way. At certain companies with foreign subsidiaries, knowing a foreign language could help.
I was a generalist life actuary who could do almost everything, but I had a specialization in investing long before that became valuable. That made me very valuable to a few life insurers that I served, as well as one hedge fund that focused on financial stocks. Eventually, I got called a “Non-traditional actuary” because I no longer worked directly in insurance or employee benefits. And I eventually dropped my FSA credential because I couldn’t justify the cost, AND the continuing education requirements, which were not relevant to what I was doing.
My guess is that you have sufficient math ability to pass the exams. Note that the actual amount of math that you need to know for work is well below what the exams test for. I never used calculus or statistics with calculus in all the time I was an actuary. The highest level math that I ever used was a quadratic equation, and that was once. Don’t get me wrong, there was a lot of math, but it was all add, subtract, multiply, and divide repeatedly, with exponentials for discounting.
Don’t pass too many exams before you seek work. Companies often don’t know what to do with those who have many exams, but no experience. Passing the first exam is enough to show the company that you are smart.
Insurance isn’t like certain investment firms that tend to be clubby, and only hire from one school. If you put your mind to it, you can likely get hired. Many firms want well-rounded actuaries that aren’t merely math nerds. Getting a mathematical result is one thing, but can you express it in such a way that marketers, underwriters and service staff can understand? Can you understand the business processes that produce the numbers? Can you tear apart the results that come out of the operating computer system for the enterprise, reverse-engineer them, and prove them to be true or false? Can you take the data from financial reporting, and feed it back to pricing, so that they can figure out whether their pricing assumptions are correct? Many insurance computer systems are inadequately designed, and being able to manipulate data for analysis can be a challenge.
A few more notes: your degrees will not hurt you… actuaries have all manner of different majors. Mine was economics. It s even possible that your degrees could come in useful at a company that writes specialty lines of property and liability insurance for various industrial firms… and engineering background can be applied in a lot of different ways.
As such, I would recommend that you join the Casualty Actuarial Society, and not the Society of Actuaries. Both are great organizations, but your background would fit the Casualty mold better. There are two other reasons to join the CAS. 1) I always found CAS members to be more businesslike than most members of the SOA. 2) There is more growth potential in P&C insurance, unless interest rates rise to the point life insurers can invest in long duration bonds to make a profit. Even then, there are so many niches in P&C insurance, whereas in life insurance and pensions opportunities are limited.
In looking for work, there are two ways to go. I have used both of them.
- Use a recruiter. Look at the ads in the National Underwriter, or any other major insurance publication and look for the ads from recruiters. Call them and talk to them. Jacobson and Associates is pretty big. But remember that the employer has to pay more for your services for the first year because of the recruiter. It could affect your salary.
- Analyze the insurers that you might want to work for. Call the Chief Actuary and ask for an informational interview (a la What Color is Your Parachute?) Talk to him, be honest, tell him what you would like to do, and ask for his honest advice. That in its own right could get you a job. It did for me as a 25-year old grad student whose Ph. D. dissertation was foundering. In many ways I seemed overqualified, but they took a chance on me at Pacific Standard Life, which three years later would be the biggest life insurance insolvency of the 1980s.
Some final notes: realize that there are a lot of insurers and actuarial consulting firms out there. Some are public, some are private, and some are mutual. If you are able to look at a membership list of the CAS or SOA, you can get quite a view of where actuaries get hired, and how many of them. You can ask the SOA or CAS to see such a document. In the old days, all actuaries received one. I don’t know what they do today.
Get a sense of where you would like to live, and what insurance-related enterprises are there. Or, do it the other way, and look at the insurance companies you might like to work for, and ask yourself if you would like to live there.
I wish you the best in your job hunt. The important thing is to get your foot in the door, and after that, demonstrate competence.
==========
To my readers: Regarding GameStop — in some ways, this is like the Go-go years of the sixties, where speculation was rampant, or like the period from 1900-1929, where wealthy men manipulated the markets for their own ends, trying to snare profits in the process, much as penny stock operators have done in the last ten years. What I would be concerned with here is that the SEC might do something stupid, and regulate stock prices the way some futures prices are regulated: if the price for the futures moves by more than a given amount, the market closes for the day. Note that that does not get rid of the volatility; it only shifts it into the future.
One more note for GameStop management (I know you read me, right?): the best thing you could do is to do a PIPE (Private investment in Public Equity) overnight and issue 30 million shares at ~$200/share to a variety of institutional investors not including Fidelity or Blackrock (unless they want to play). What would this do?
- All of your 10%+ holders would be free to sell their shares, because their stakes would be below 10%.
- You would have more than enough money to retire all of your debt and then some.
- With the remaining $5 billion bucks, you could be assured of a happy outcome where the GME stock price is over $50, and you would have time to consider how to restructure the firm into some business that actually has a future. The only ones that lose are the idiots who believe in magic, and think that stock prices don’t reflect economic realities, only trading values.
Anyway, what I said last night still applies — in the long run the price of GME will fall. Bubbles can only be sustained by an ever-larger amount of money buying in, which is impossible. Eventually, people need the money to live, rather than speculate.