
Idea Credit: Philosophical Economics Blog
My most recent post,?Estimating Future Stock Returns?was well-received. ?I expected as much. ?I presented it as part of a larger presentation to a session at the Society of Actuaries 2015 Investment Symposium, and a recent meeting of the Baltimore Chapter of the AAII. ?Both groups found it to be one of the interesting aspects of my presentation.
This post is meant to answer three reasonable questions that got posed:
- How do you estimate the model?
- How do we understand what it is forecasting given multiple forecast horizons seemingly implied by the model?
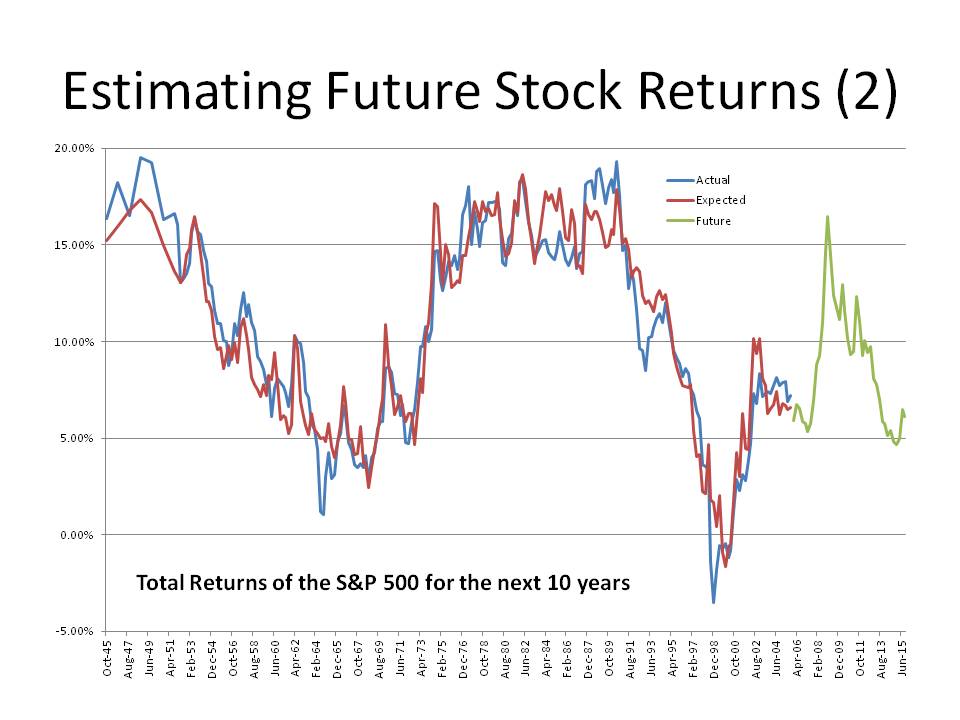
- Why didn’t the model how badly the market would do in 2001 and 2008? ?And I will add 1973-4 for good measure.
Ready? ?Let’s go!
How to Estimate
In his original piece, @Jesse_Livermore freely gave the data and equation out that he used. ?I will do that as well. ?About a year before I wrote this, I corresponded with him by email, asking if he had noticed that the Fed changed some of the data in the series that?his variable used retroactively. ?That was interesting, and a harbinger for what would follow. ?(Strange things happen when you rely on government data. ?They don’t care what others use it for.)
In 2015, the Fed discontinued one of the series that was used in the original calculation. ?I noticed that when the latest Z.1 report came out, and I tried to estimate it the old way. ?That threw me for a loop, and so I tried to re-estimate the relationship using what data was there. ?That led me to do the following:
- Use this data series from FRED: [A]?Nonfinancial corporate business; corporate equities; liability, Level, and
- use these three series from the Federal Reserve: [B] Domestic nonfinancial sectors; debt securities and loans; liability, [C] Rest of the world; debt securities and loans; liability, and [D]?Domestic financial sectors; corporate equities; liability
I tried to get all of them from one source, and could not figure out how to do it. ?The Z.1 report has all four variables in it, but somehow, the Fed’s Data Download Program, which one of my friends at a small hedge fund charitably referred to as “finicky” did not have that series, and somehow FRED did. ?(I don’t get that, but then there are a lot of things that I don’t get. ?This is not one of those times when I say, “Actually, I do get it; I just don’t like it.” ?That said, like that great moral philosopher Lucy van Pelt, I haven’t ruled out stupidity yet. ?To which I add, including my stupidity.)
The variable is calculated like this:
(A + D)/(A + B + C + D)
Not too hard, huh? ?The R-squared is just a touch lower from estimating it the old way… but the difference is not statistically significant. ?The estimation is just a simple ordinary least squares regression using that single variable as the independent variable, and the dependent variable being the total return on the S&P 500.
As an aside, I tested the variable over other forecast horizons, and it worked best over 10-11 years. ?On individual years, the model is most powerful at predicting the next year (surprise!), and gets progressively weaker with each successive individual year.
To make it concrete: you can use this model to forecast the expected returns for 2016, 2017, 2018, etc. ?It won’t be very accurate, but you can do it. ?The model gets more accurate forecasting over a longer period of time, because the vagaries of individual years average out. ?After 10-11 years, the variable is useless, so if I were put in charge of setting stock market earnings assumptions for a pension plan, I would do it as a step function, 6% for the next 10 years, and 9.5% per year thereafter… or in place of 9.5% whatever your estimate is for what the market should return normally.
On Multiple Forecast Horizons
One reader commented:
I would like to make a small observation if I may. If the 16% per annum from Mar 2009 is correct we still have a 40%+ move to make over the next three years. 670 (SPX March 09) growing at 16% per year yields 2900 +/- in 2019. With the SPX at 2050 we have a way to go. If the 2019 prediction is correct, then the returns after 2019 are going to be abysmal.
The first answer would be that you have to net dividends out. ?In March of 2009, the S&P 500 had a dividend yield of around 4%, which quickly fell as the market rose and dividends fell for about one year. ?Taking the dividends into account, we only need to get to 2270 or so by the March?of 2019, works out to 3.1% per year. ?Then add back a dividend yield of about 2.2%, and you are at a more reasonable 5.3%/year.
That said, I would encourage you to keep your eye on the bouncing ball (and sing along with Mitch… does that date me…?). ?Always look at the new forecast. ?Old forecasts aren’t magic — they’re just the best estimate a single point in time. ?That estimate becomes obsolete as conditions change, and people adjust their portfolio holdings to hold proportionately more or less stocks. ?The seven year old forecast may get to its spot in three years, or it may not — no model is perfect, but this one does pretty well.
What of 2001 and 2008? ?(And 1973-4?)
Another reader wrote:
Interesting post and impressive fit for the 10 year expected returns. ?What I noticed in the last graph (total return) is, that the drawdowns from 2001 and 2008 were not forecasted at all. They look quite small on the log-scale and in the long run but cause lot of pain in the short run.
Markets have noise, particularly during bear markets. ?The market goes up like an escalator, and goes down like an elevator. ?What happens in the last year of a ten-year forecast is a more severe version of what the prior questioner asked about the 2009 forecast of 2019.
As such, you can’t expect miracles. ?The thing that is notable is how well this model did versus alternatives, and you need to look at the graph in this article to see it (which was at the top of the last piece). ?(The logarithmic graph is meant for a different purpose.)
Looking at 1973-4, 2001-2 and 2008-9, the model missed by 3-5%/year each time at the lows for the bear market. ?That is a big miss, but it’s a lot smaller than other models missed by, if starting 10 years earlier. ?That said, this model would have told you prior to each bear market that future rewards seemed low — at 5%, -2%, and 5% respectively for the ?next ten years.
Conclusion
No model is perfect. ?All models have limitations. ?That said, this one is pretty useful if you know what it is good for, and its limitations.
I think I managed to add series (A) you linked to on FRED to your FED package.
You need to select the “3 Input series with zero seasonal factor” as the “Series Type” for it to appear. The data in the FED series “Z1/Z1/FL103164115.Q 1945Q4 2015Q4 281 Nonfinancial corporate business; public corporate equities less intercompany holdings; liability” is identical to the series you linked to (A) on FRED:
Here is the link to the FED bundle: http://www.federalreserve.gov/datadownload/Review.aspx?rel=Z1&series=ea7b69148fbcdad1223d74413a0a4a42&lastObs=7&from=&to=&filetype=csv&label=include&layout=seriescolumn
I included the wrong series name and link.
The correct link is: http://www.federalreserve.gov/datadownload/Download.aspx?rel=Z1&series=957bb2c7b887b758c261be13b998ee9e&filetype=csv&label=include&layout=seriescolumn&from=03/01/1945&to=12/31/2015
For series added: “Z1/Z1/FL103164103.Q 1945Q4 2015Q4 281 Nonfinancial corporate business; corporate equities; liability”
Bas,
Kudos and Thanks. I was secretly hoping that one of my readers would get one system or the other to produce a unified feed. It works, and I really appreciate it. When I do an update, I will feature this and mention you.
Again, thanks.
David